
When configuring either a process parameter or a processor source, one of the first choices you will see is the run mode. By default, this will be set to Any input updated. But what does this mean, and when should you change the run mode?
The default setting means that whenever any input parameter defined by the process advances beyond the current time of the process, then the process will be triggered to run. Consider a process that defines two inputs, param1 and param2, which will be summed by the process. We will start with the process and both the inputs sharing the same current time of 03:00
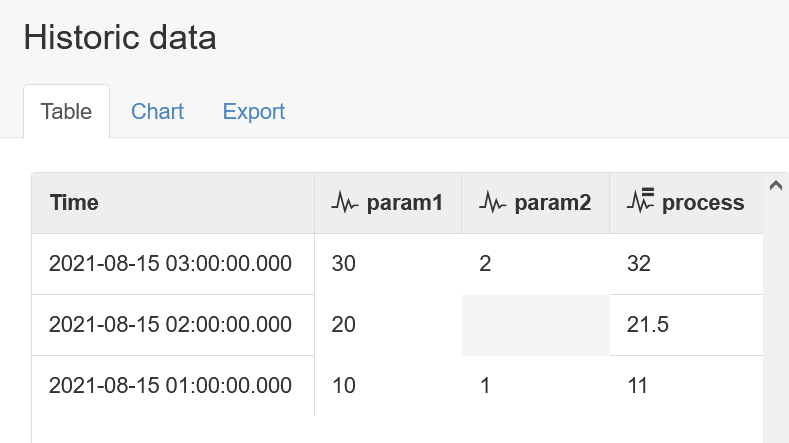
And the run mode is set to the default, which is Any input updated:
If we now acquire 2 new records, but only for param1, let's see how this has affected the process:
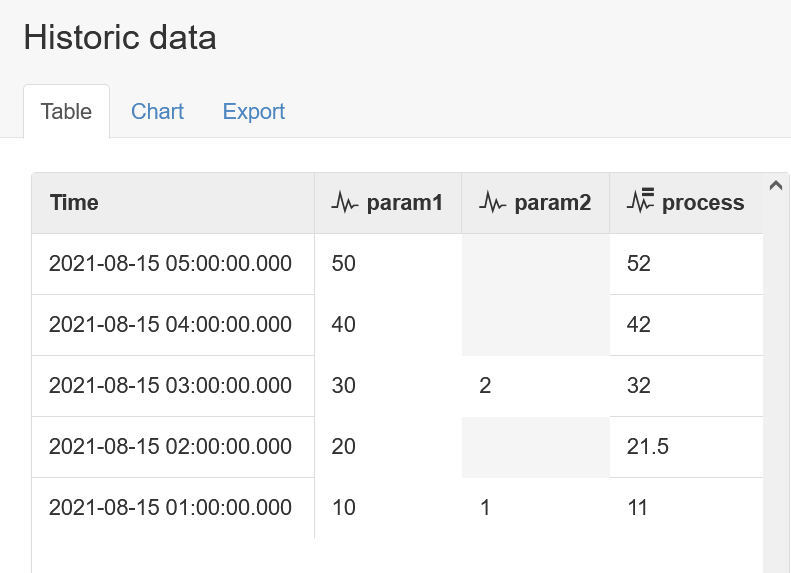
Since the process is configured to be triggered by any input being updated, and param1 was just updated, then the process will be triggered, despite no new data for param2. The process does it's job of summing the two parameters, but note that records from different times have being summed. Specifically, new values from param1 at the 04:00 and 05:00 times have been summed with the most recent value of param2 which is still back at 03:00.
This may be desirable behavior for some use cases where input values don't need to have aligning times for the process calculation to be useful. However, what if your process represents a calculation that should only be run when all inputs have updated? Then the run mode can be changed to All inputs updated:
Let's reset to the same starting scenario:
And lets acquire the 2 new records for param1 again, and view the result:
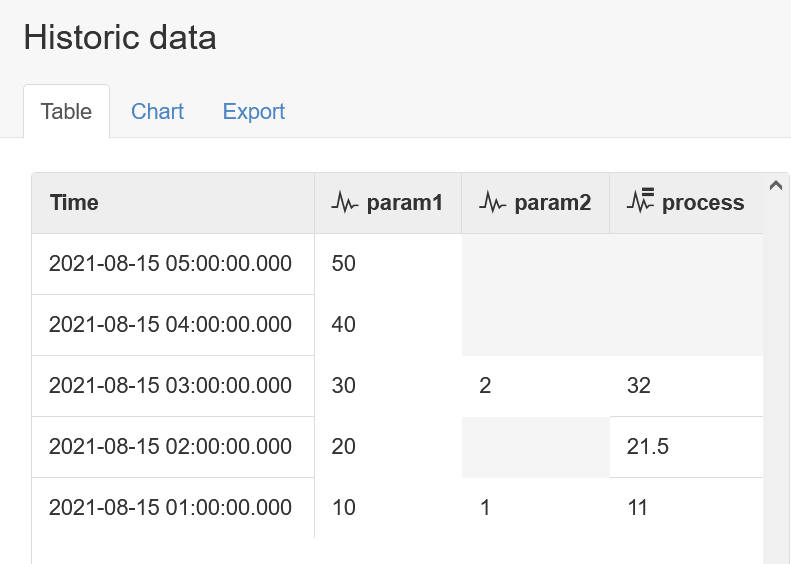
This time, the process has not advanced beyond it's original current time of 03:00, because to do so now require all inputs to advance beyond that time. Since param2 has not advanced, neither will the process.
If we now advance param2, but only by 1 record at 04:00, the process will be updated accordingly:
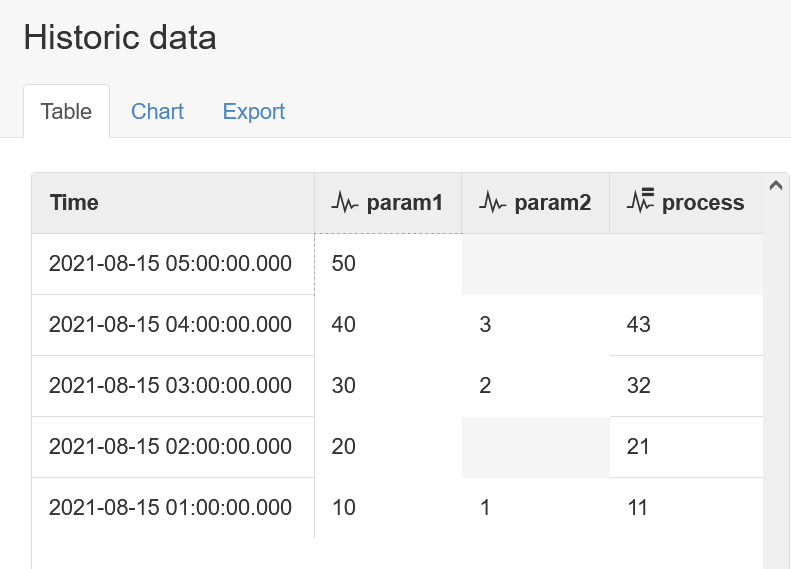
It now appears that we have demonstrated the two possible outcomes that will occur for each of the two choices of run mode. However, there is a very important extra detail which should not be overlooked:
A process parameter will only ever execute in the context of it's primary input.
That is, the timestamps of the primary input (which is always the first input parameter defined in the process code) will determine the timestamps of the process outputs. There are some variations to this when aggregation is involved, but for raw values like we have been demonstrating with, the rule is clear: without a value for the primary input, no calculation will take place and there will be no process output at the corresponding time. This rule overrides the run mode configuration, which can be clearly demonstrated by first switching back to a run mode of Any input updated:
And resetting to the same start conditions as before:
But this time, we will acquire new records only for param2. Despite the run mode suggesting that any updated input (including param2) will trigger the process, we can see that this doesn't happen:
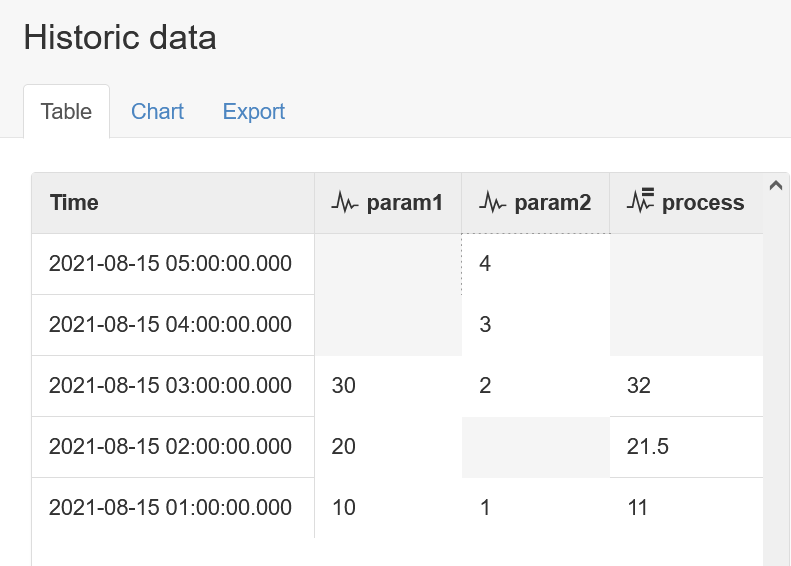
It's only when the primary input (param1) is acquired again that the process will be triggered and produce new output values. For example, acquiring 1 new record from param1 will now result in 1 new output value from the process:
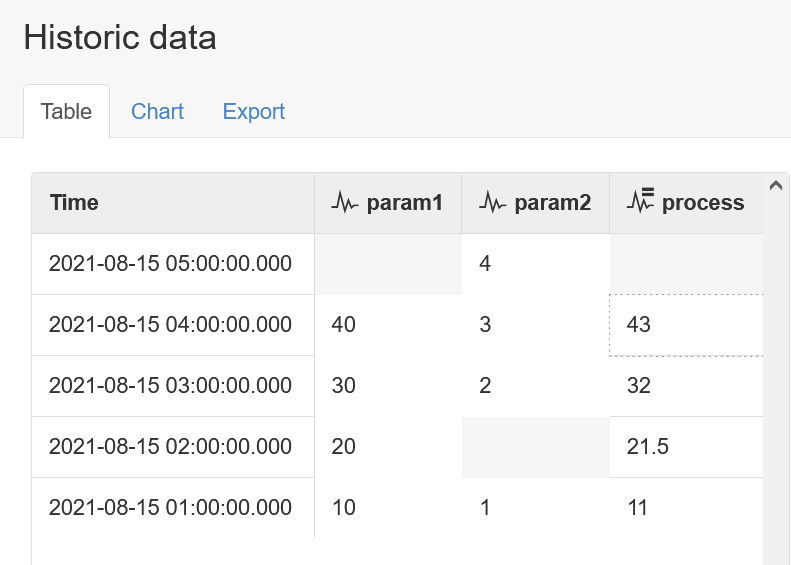
This behavior is despite the run mode currently being configured as Any input updated.
Let's observe one more example of how significant the primary input is. In this case, both param1 and param2 have a gap at different times in their respective data series: param1 is missing data at 04:00, while param2 is missing data at 02:00. Remember that the process will only execute for timestamps defined by the primary input, param1. Accordingly, we can see that the process is still able to produce an output value at 02:00 even though param2 is missing (in this case it interpolates a value of 1.5 for param2 and uses that in the calculation). But at 04:00 when we are missing param1, the process does not execute so no output value is produced.
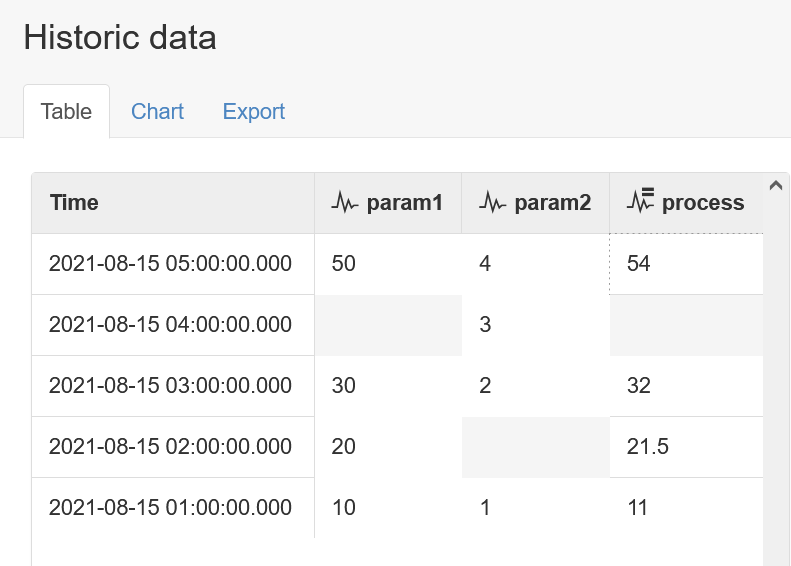
In summary, choose the run mode that is appropriate for your use case, but remember that the choice of which input is defined first in your process code can make a big difference.